Clustering Example in R 4 Crucial Steps You Should Know Datanovia
While calculating the mean of a numeric vector is straightforward, you often need to calculate the mean for specific groups within your data. This involves two steps: grouping the data and applying the mean() function to each group. R provides several methods to accomplish this task, including the use of the dplyr package, the aggregate.
Comparing Means In R Easy Guides Wiki Sthda Hot Sex Picture

Here is how to calculate the mean by a group in R. If you are an Excel, user you might prefer to say average by a group in R. This post contains multiple scenarios that will ensure that you know some of the pitfalls and tricks. I will use the airquality dataset, which is available in R. This dataset contains columns like temperature with.
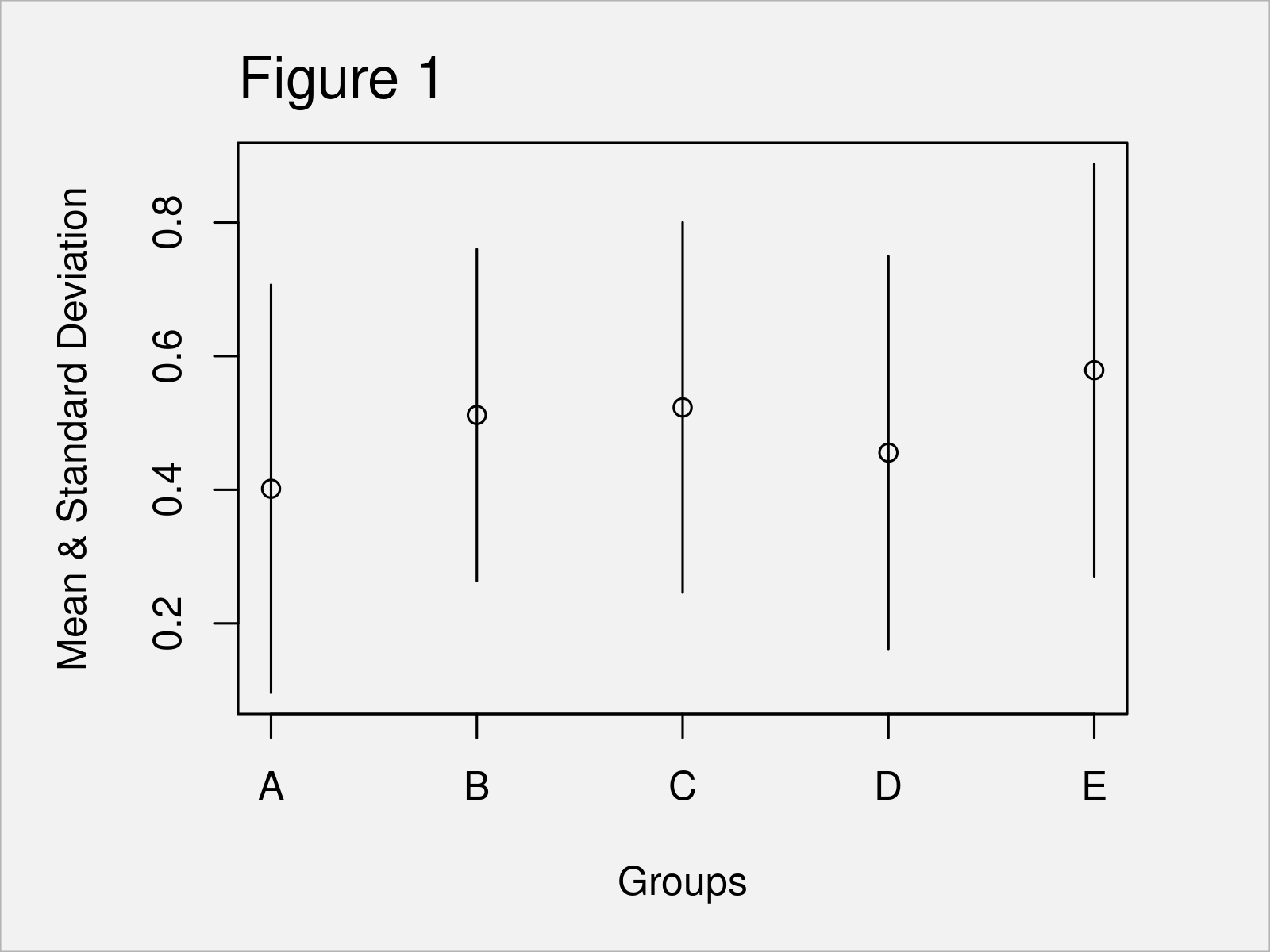
Plot Mean & Standard Deviation by Group (Example) Base R & ggplot2
2. Perform Group By Mean on a Single Column in R . To calculate the group by mean or average in an R data frame, you can use the group_by() function in combination with the summarise() from the dplyr package. The group_by() function creates a grouped data frame based on specified single/multiple columns. You can apply the summarise() function on grouped data to calculate the mean or average.
R Basic Graphs 2 With Ggplot2 Rudolf Cardinal Bar Chart Chart Riset
Group_by means for multiple columns in R. 2. Get mean values if a key column value is duplicated with dplyr (R) 1. translating stata code to R about calculating means by group and years. 0. Group wise mean of each columns in a Data frame in R. 3. Summarise multiple variables by one group at a time. 1.
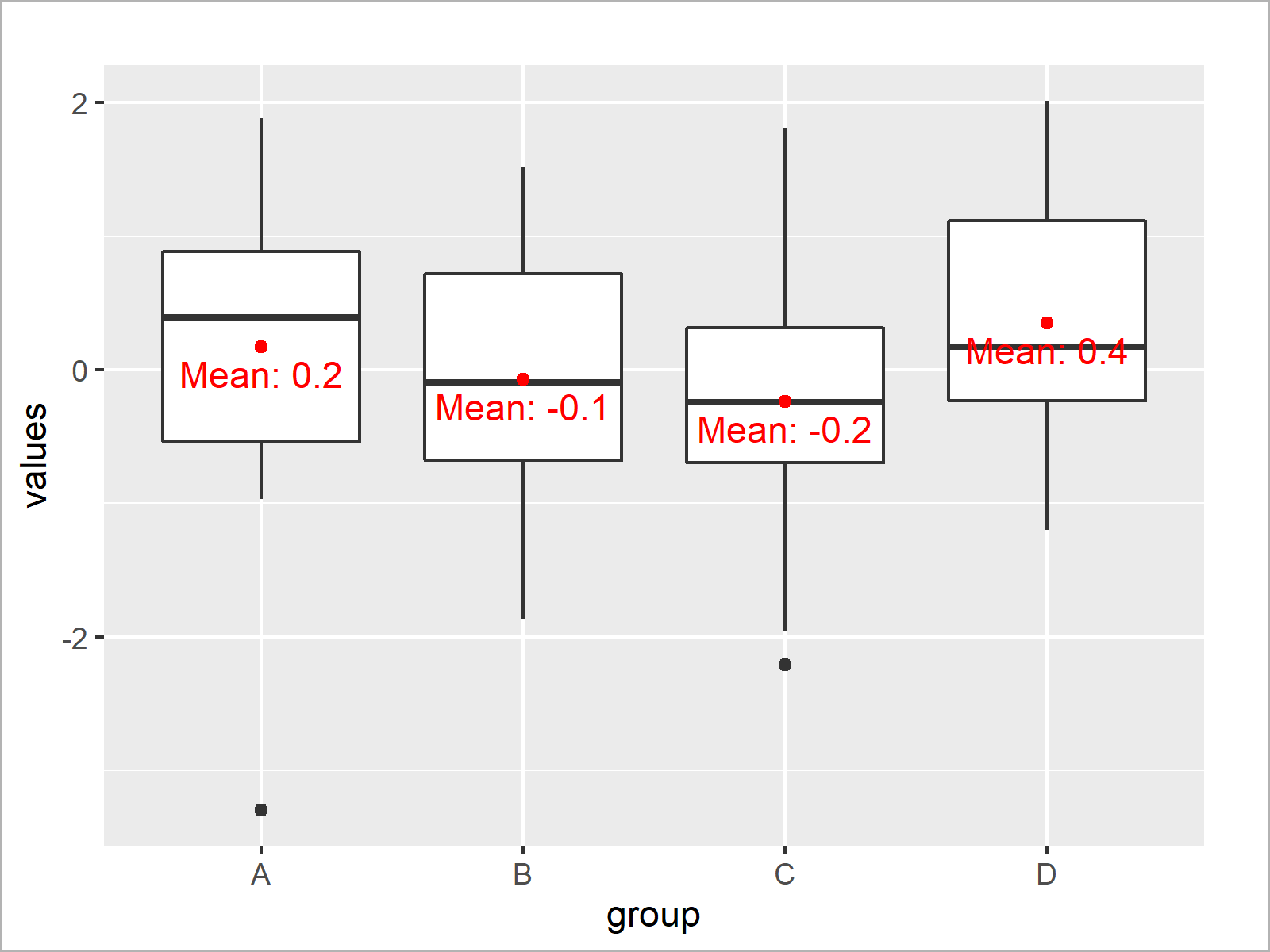
Draw Boxplot with Means in R (2 Examples) Add Mean Values to Graph
How to compute the mean by group in the R programming language. More details: https://statisticsglobe.com/mean-by-group-in-rR code of this video: data(iris).
What is The Meaning of Group ? The Different Types of Groups Explained In A Simple Way

6.3 group_by() and ungroup() 6.3. group_by() and. ungroup() Takes existing data and groups specific variables together for future operations. Many operations are performed on groups. Example: Grouping by age and sex (male/female) might be useful in a dataset if we care about how females of a certain age scored compared to males of a certain age.
Rgroup replacement database for medicinal chemistry Future Science OA

In ungroup(), variables to remove from the grouping. When FALSE, the default, group_by() will override existing groups. To add to the existing groups, use .add = TRUE. This argument was previously called add, but that prevented creating a new grouping variable called add, and conflicts with our naming conventions.
Calculate Mean by Group in Python (2 Examples) Average for Subgroups
library (data.table) dt[ ,list(mean= mean (col_to_aggregate)), by=col_to_group_by] The following examples show how to use each of these methods in practice. Method 1: Calculate Mean by Group Using Base R. The following code shows how to use the aggregate() function from base R to calculate the mean points scored by team in the following data frame:
R How To Create A Stacked Bar Chart In Ggplot2 With Total Frequency Hot Sex Picture
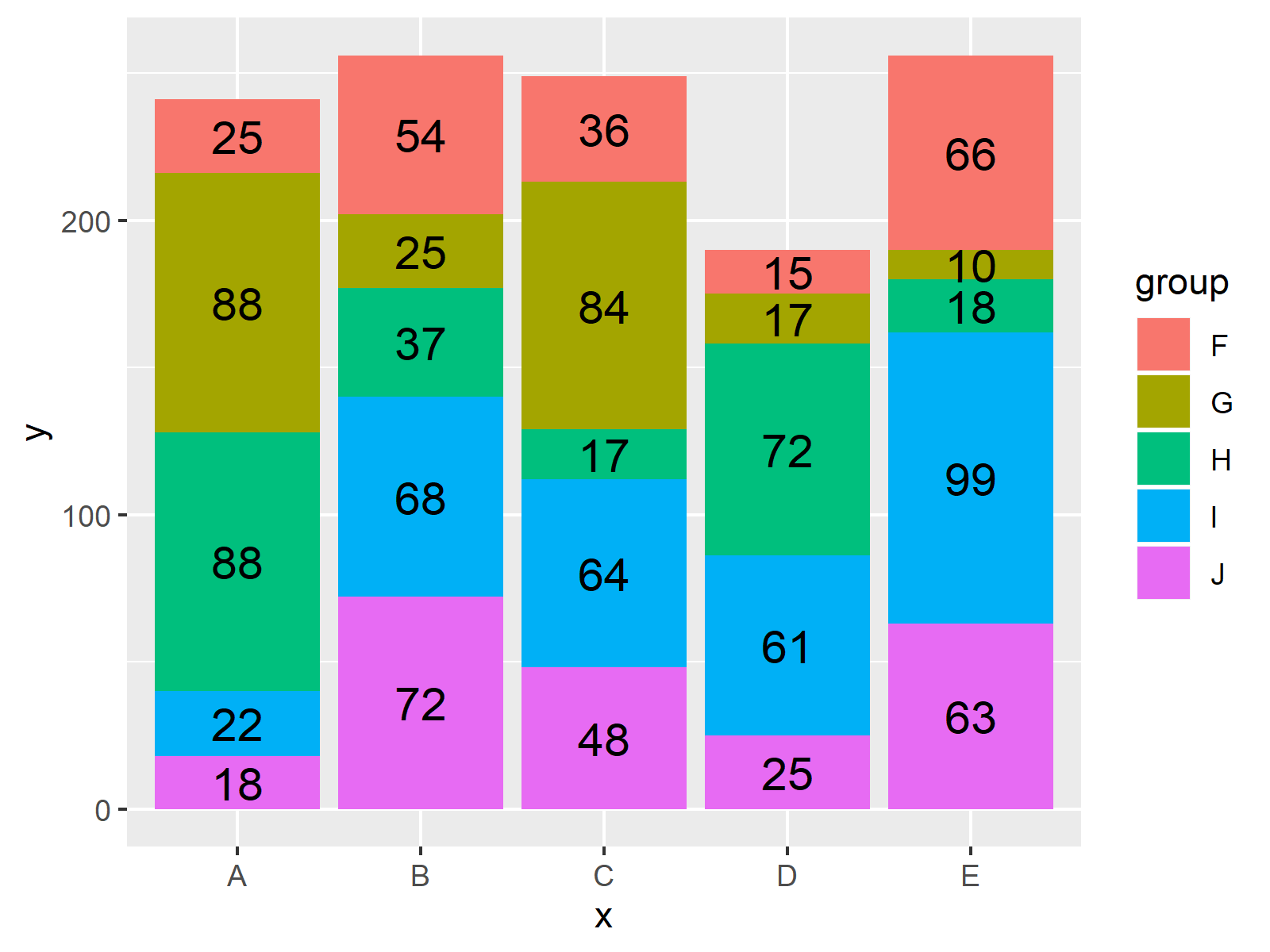
There are many ways to do this in R. Specifically, by, aggregate, split, and plyr, cast, tapply, data.table, dplyr, and so forth. Broadly speaking, these problems are of the form split-apply-combine. Hadley Wickham has written a beautiful article that will give you deeper insight into the whole category of problems, and it is well worth reading. His plyr package implements the strategy for.
R How To Plot The Mean By Group In A Boxplot In Ggplot Stack Overflow Vrogue
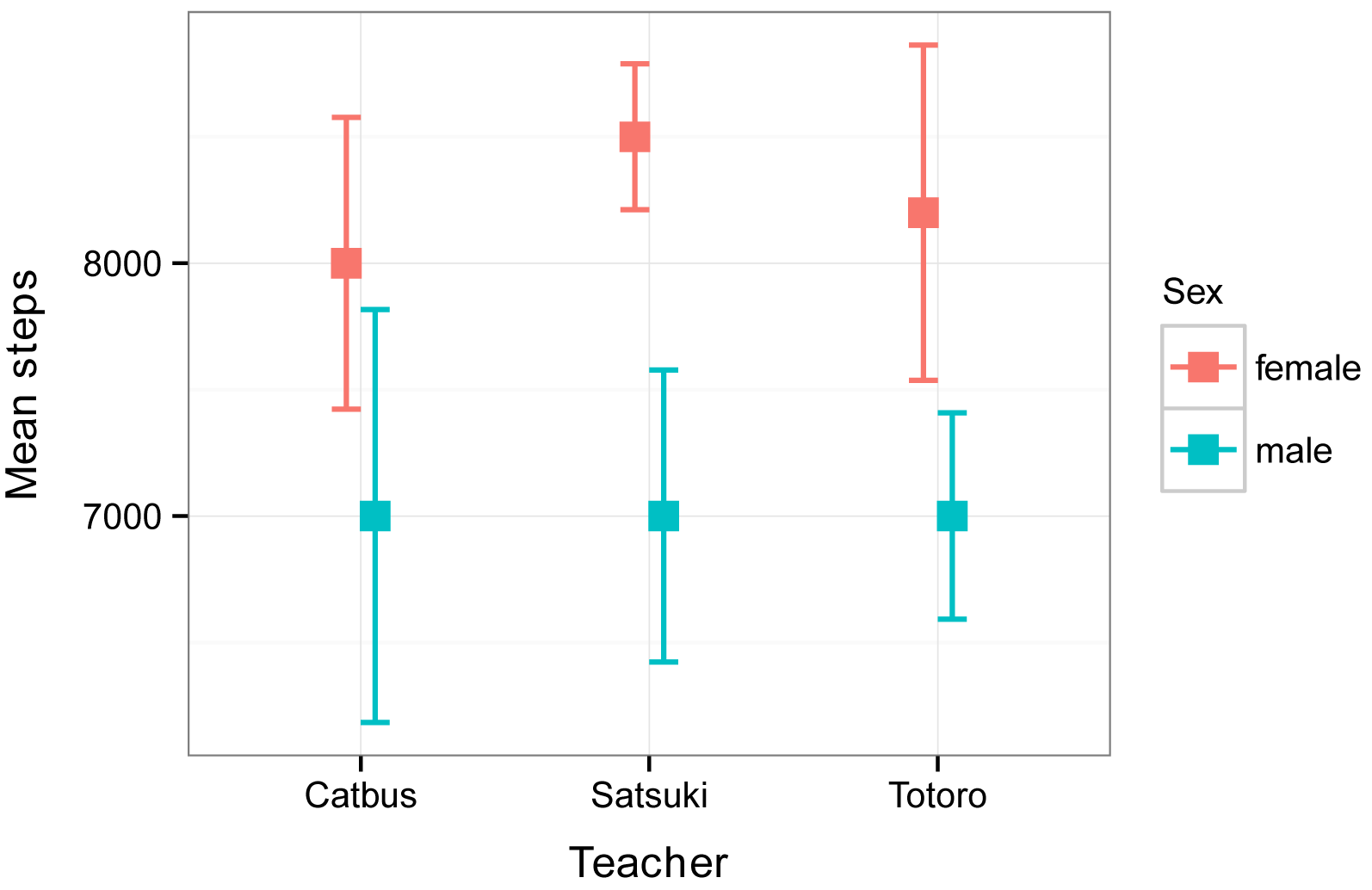
An alternative function (statsBy) returns a list of means, n, and standard deviations for each group. This is particularly useful if finding weighted correlations of group means using cor.wt. More importantly, it does a proper within and between group decomposition of the correlation. cohen.d will work for two groups. It converts the data into.
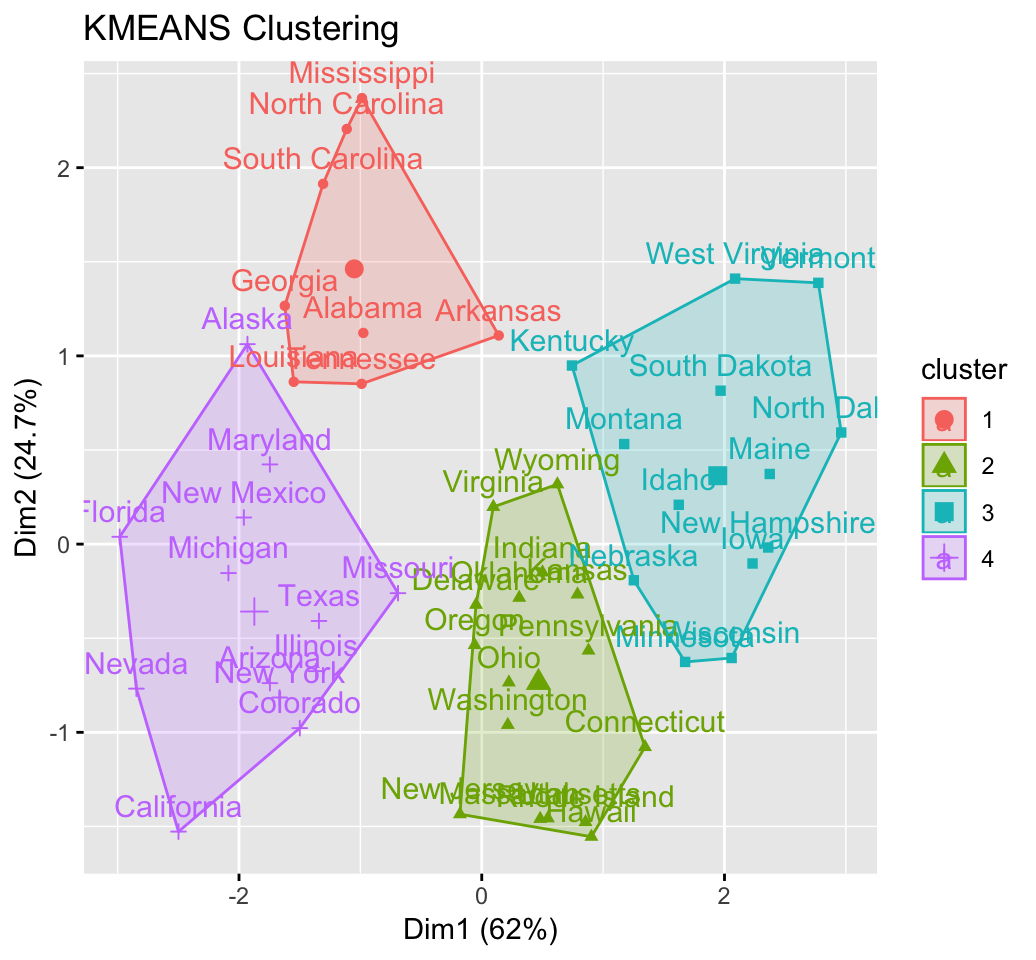
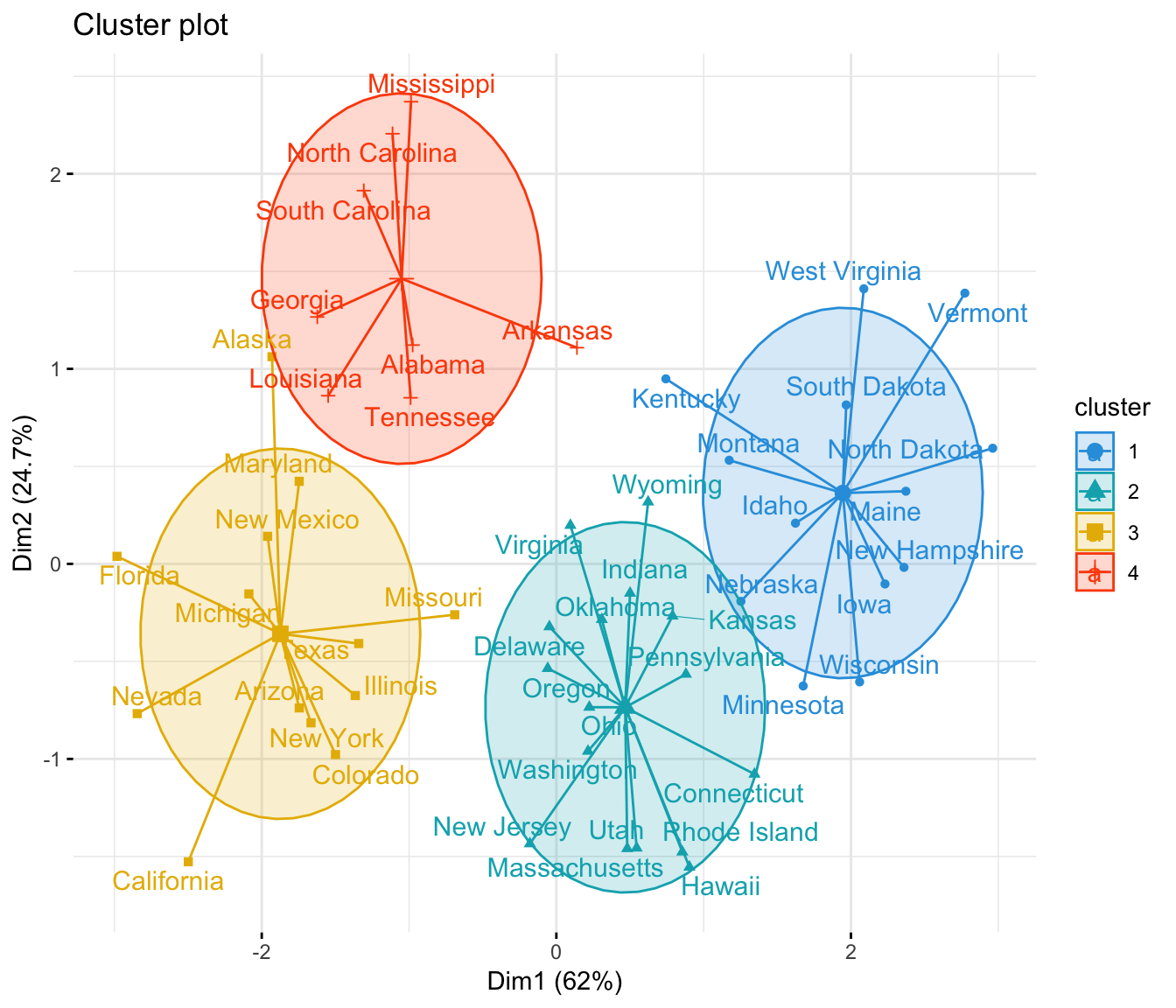
KMeans Clustering Visualization in R Step By Step Guide Datanovia
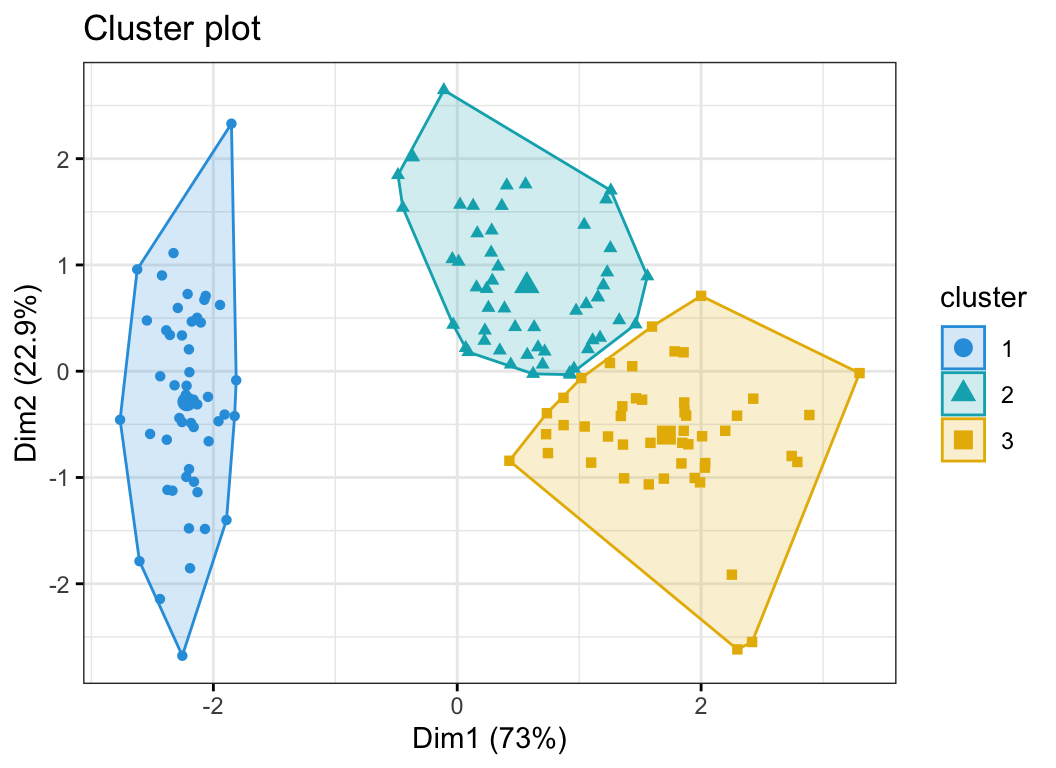
Pleleminary tasks. Launch RStudio as described here: Running RStudio and setting up your working directory. Prepare your data as described here: Best practices for preparing your data and save it in an external .txt tab or .csv files. Import your data into R as described here: Fast reading of data from txt|csv files into R: readr package.. Here, we'll use the R built-in ToothGrowth data set.
what are Rgroups? YouTube

The RStudio console output shows the mean by group: The setosa group has a mean of 5.006, the versicolor group has a mean of 5.936, and the virginica group has a mean of 6.588. Note: By replacing the FUN argument of the aggregate function, we can also compute other metrics such as the median, the mode, the variance, or the standard deviation.
Plot Mean & Standard Deviation by Group (Example) Base R & ggplot2
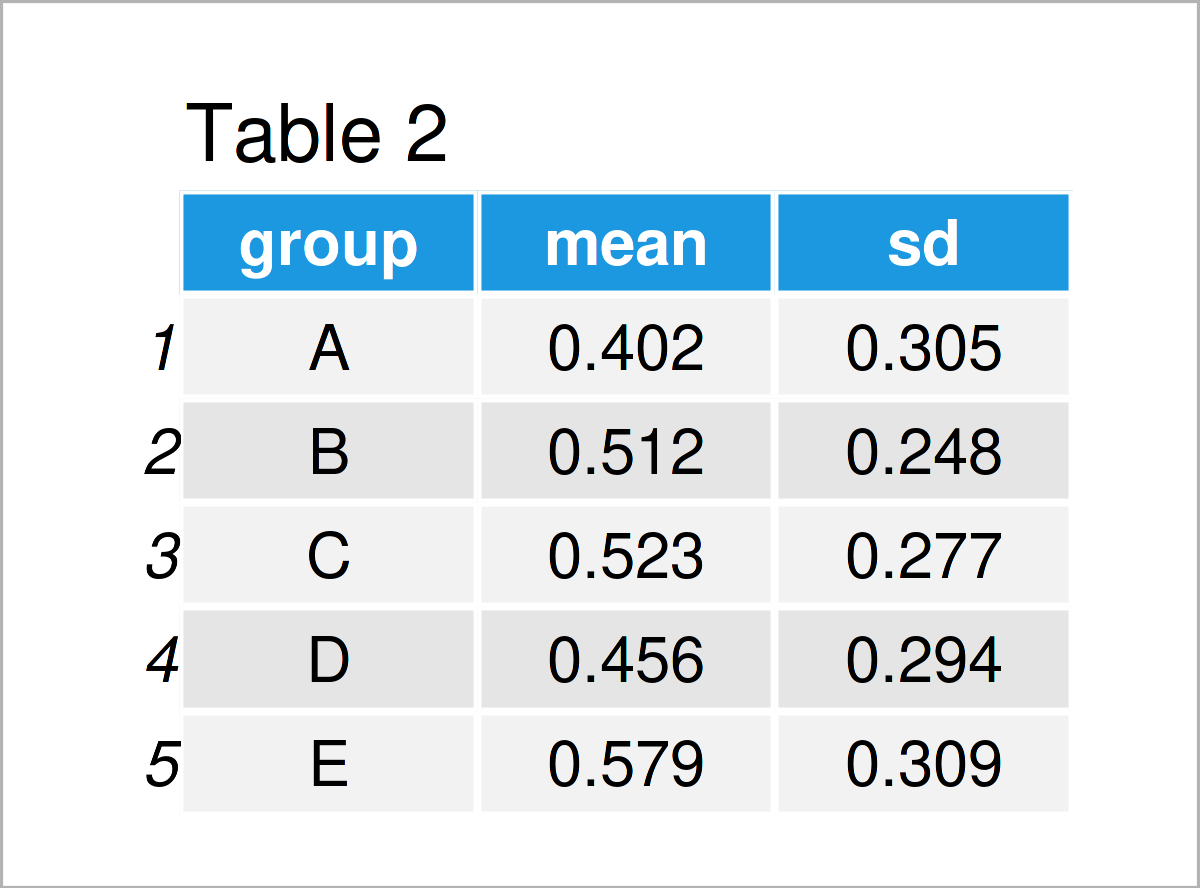
How to Group Data With R. Load the data set into Tibble. Enter the function group_by to group the information. Use summarise to analyze your data. Create a new column with mutate. Ungroup your data with ungroup (). Grouping data is undeniably essential for data analysis, and I'll investigate some of the methods for doing so with R, Tidyverse.
KMeans Clustering in R Algorithm and Practical Examples Datanovia
Details. This function is comparable to aggregate(x, group, mean), but provides some further information, including summary statistics from a One-Way-ANOVA using x as dependent and group as independent variable.emmeans::contrast() is used to get p-values for each sub-group. P-values indicate whether each group-mean is significantly different from the total mean.
How to Determine the R and S configuration Chemistry Steps

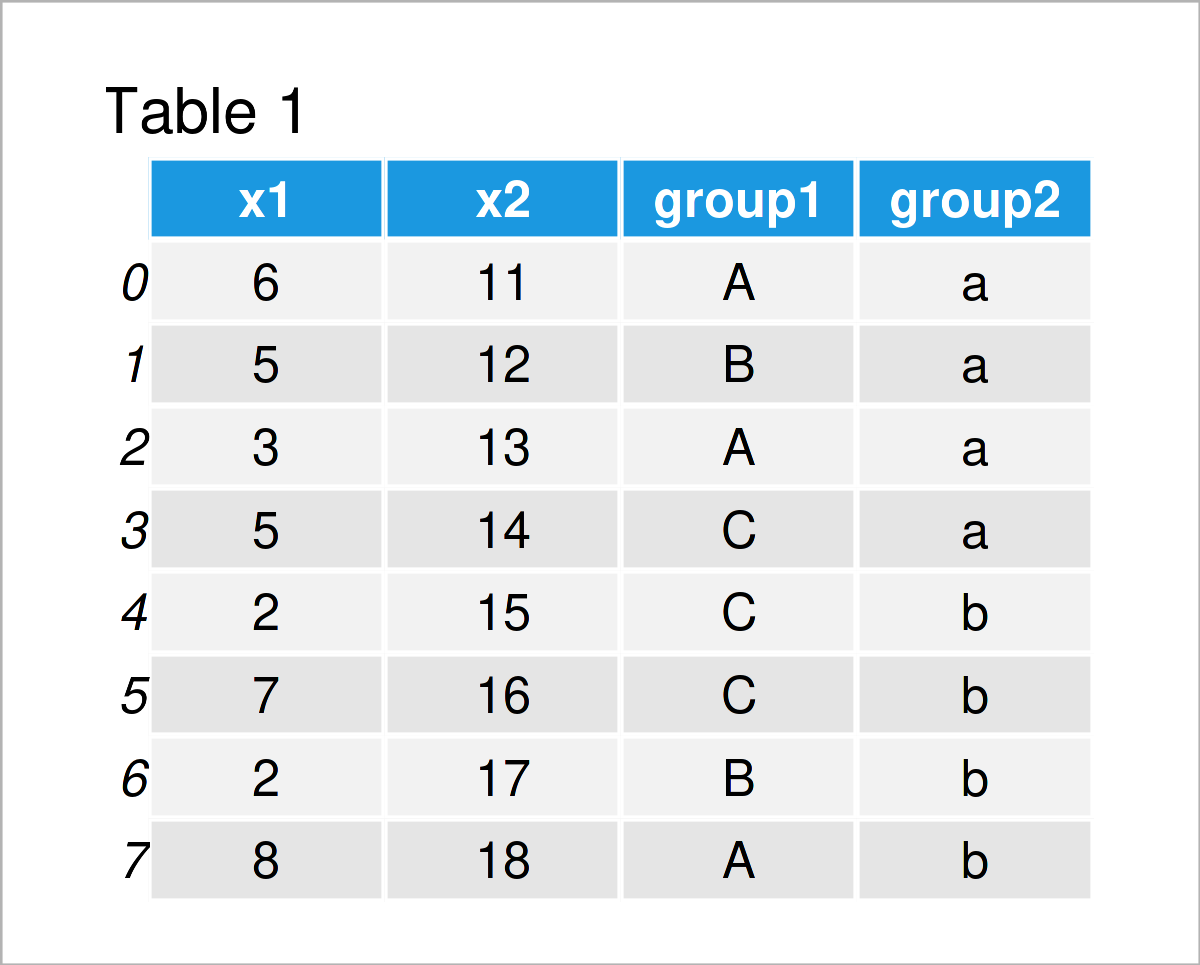
> ft mean sd group level 1 A 11 1 B 10 3 C 10 1 2 A 9 1 B 11 2 C 8 0 3 A 10 1 B 10 2 C 10 0 Beautiful, isn't it? You can export this table to a pdf with the textplot() function of the gplots package. See here for others' solutions. Share. Cite. edited Oct 23, 2013 at.
[Solved]How to plot the mean by group in a boxplot in ggplotR
dimnames=list(names(b),col.names=names(b[[1]])) )) } The idea is the same as a SAS MEANS BY statement. The function 'means.by' takes a data.frame and an indexing variable and computes the mean over the columns of the data.frame for each set of rows corresponding to the unique values of INDEX and returns a new data frame with with the row names.
.

